
Auf der Arbeit benutzen wir zur Datenhaltung der aufgenommenen Messwerte unserer Synthesen Postgresql als DBMS.
Zwar befinden sich die Client-PCs auf denen die Steuerungssoftware ausgeführt wird in einem eigenen, abgeschotteten Labornetz, jedoch müssen wir auch den Fall behandeln, falls der Datenbank-Server nicht erreichbar ist (wie zum Beispiel bei einem Netzwerkausfall). Außerdem ist es schöner, wenn die Clients keinen direkten Zugriff auf die Datenbank benötigen, weshalb wir die Software umstrukturiert haben und nun einen Message-Broker als Middleware einsetzen.
RabbitMQ to the Rescue
Durch den Einsatz von RabbitMQ als Message-Broker kann unser System nicht nur Netzwerkausfälle abfangen, es werden auch automatisch die aufgenommenen Daten dann übertragen, sobald die Verbindung wiederhergestellt wurde.
Dafür haben wir sowohl auf unserem Server, als auch den Client-PCs, an welchen die Synthesen durchgeführt werden, Erlang und RabbitMQ installiert, auf dem Server einen Nutzer eingerichtet (um Daten von einem Client dorthin übertragen zu dürfen) und die Software so angepasst, dass wir JSON-Nachrichten verschicken.
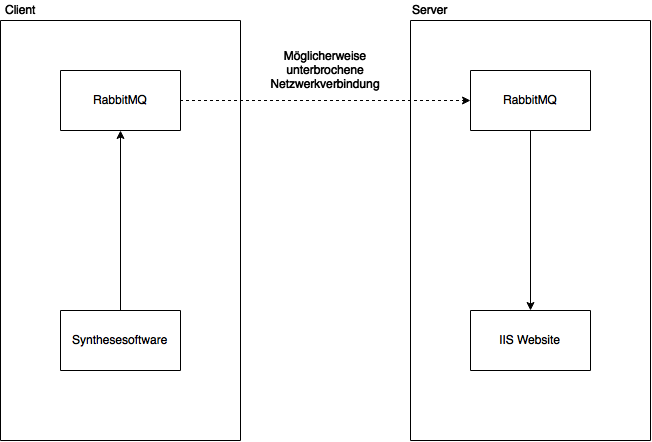
Innerhalb der IIS-Website werden beim Start 4 RabbitMQ-Worker-Instanzen gespawnt, die permanent laufen und somit die gesendeten Nachrichten verarbeiten und in die Datenbank eintragen.
Die Daten werden vom Client via Shovel-Plugin auf den Server übertragen.
Datensicherheit
Da die Daten ankommen müssen und nicht verloren gehen dürfen, ist es wichtig, dass wir die Queues auf Durable stellen. Somit werden die Nachrichten beim Eingang auf die Festplatte gespeichert werden, und erst beim Empfang der Nachricht an der Gegenstelle von dort gelöscht. Genau so haben wir es beim Abruf der Daten innerhalb der IIS-Website gemacht, wo die Nachricht erst Acknowledged werden, wenn der Eintrag in die Datenbank Erfolgreich war.
Performance Benchmarking
Die einzige Frage, die sich dann noch Stellen würde, wäre, ob das System in der Lage ist die Daten in Echtzeit zu verarbeiten (solange die Netzwerkverbindung besteht natürlich), oder ob wir eventuell mehr Worker-Instanzen auf dem Server spawnen müssen, oder sogar einen zweiten Server benötigen.
Im Regelfall haben wir Maximal 20 Nachrichten pro Sekunde, die vom Client ausgehen (welche Aktionen durchgeführt wurden, ob ein Ereignis eingetreten ist, Messwerte wie Temperatur und Aktivität). Da wir jedoch mehrere Clients haben, die Nachrichten erzeugen, können wir grob 200 Nachrichten als oberstes Maximum rechnen (< 10 Apparaturen, nicht immer alle gleichzeitig im Betrieb).
Das Netzwerk ist mit 100MBit ausreichend dimensioniert, das einzige verbleibende Problem könnte dann jedoch das persistieren der Daten sein.
Erste Tests haben gezeigt, dass wir im aktuellen Setup rund 500 Nachrichten pro Sekunde verarbeiten können, könnten jedoch noch mehr Worker-Threads spawnen und die Anzahl noch etwas steigern.
Vorteil der Echtzeit-Verarbeitung
Durch die Echtzeit-Verarbeitung ist es uns möglich laufende Synthesen Live am PC zu Verfolgen. Das ist zwar nicht unbedingt nötig, aber dennoch ein nettes Feature.
Alles in Allem eine Erfolgreiche Aktion.
Achte mal darauf wie du deine Sätze strukturierst und Satzzeichen richtig setzt.
Auf der Arbeit benutzen wir zur Datenhaltung der aufgenommenen Messwerte unserer Synthesen Postgresql als DBMS.
Zwar befinden sich die Client-PCs auf denen die Steuerungssoftware ausgeführt wird in einem eigenen, abgeschotteten Labornetz, jedoch müssen wir auch den Fall behandeln, falls der Datenbank-Server nicht erreichbar ist (wie zum Beispiel bei einem Netzwerkausfall).
So würde ich es formulieren:
Auf der Arbeit benutzen wir zur Datenhaltung, der aufgenommenen Messwerte unserer Synthesen, Postgresql als DBMS.
Die Client-Rechner, auf denen die Steuerungssoftware ausgeführt wird, in einem eigenen, abgeschottetem Labornetz. Jedoch müssen wir auch den Fall behandeln, beispielsweise bei einem Netzwerkausfall, dass der Datenbank-Server nicht erreichbar ist.
Hört sich doch viel besser an.
In deiner Verbesserung fehlt aber mindestens ein Verb. Außerdem ist das ein Blog und keine wissenschaftliche Abhandlung oder ein Paper, da kann ich Gott sei dank so schreiben, wie ich es für richtig halte.
Für themenbezogene Diskussionen bin ich jederzeit zu haben, aber die Rechtschreibung und Zeichensetzung korrigieren, nee da bin ich raus.